

Microsoft Azure Machine Learning Studio(クラシック)とは
公式ドキュメントはこちらです。
ざっくり言うと、クラウドリソースを活用しながら様々な機械学習手法(アルゴリズム)を用いて任意のデータについて予測分析のできるツールです。
容量制限(10GB)があったりしますが、無料でも運用できます。
先日ご紹介しましたSONYの『Prediction One』よりは導入のハードルが若干高いかもしれませんが、少し慣れれば、ノンコーディングで簡単に予測結果を得ることができます。

準備
データのインポート
まずは、こちらからサインイン。
先にデータをインポートしておきましょう。
画面左のメニューより[DATASETS]を選択。左下の[+NEW]をクリック。
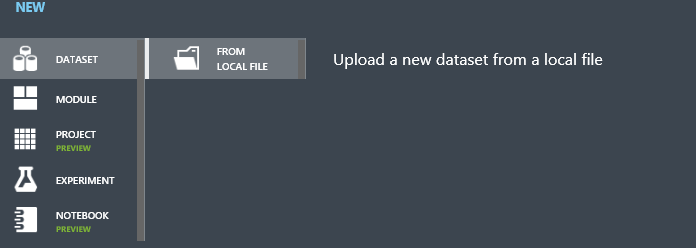
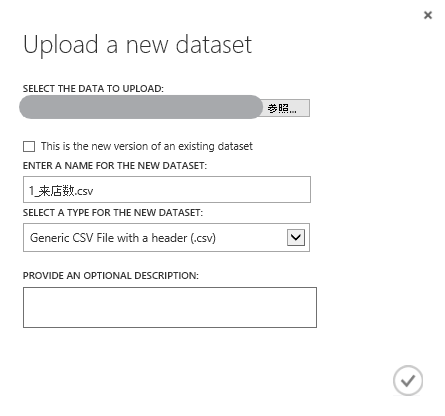
[FROM LOCAL FILE]をクリック。
今回は、『Prediction One』のサンプルデータとして用意されている来店数のCSVを使います。
中身は以下のようになっています。
| 日付 | 気温 | 曜日 | 祝日フラグ | 前年来店数 | 先週の平均来店数 | 来店数(ターゲット) |
| 2019/7/19 | 26.5℃ | 金 | 0 | 287 | 352.1 | 390 |
気温や日付情報、前年・前週の実績から今年の当該日付の来店数を予測する問題でしたね。
最終的に両者(Microsoft Azure Machine Learning Studio(クラシック)とPrediction One)の精度比較がしやすいかなというところと…データの準備が面倒でしたすみません。
実験スペースの作成
データのインポートが終わったら、実験スペースの作成をします。
画面左のメニューより[EXPERIMENTS]を選択。左下の[+NEW]をクリック。
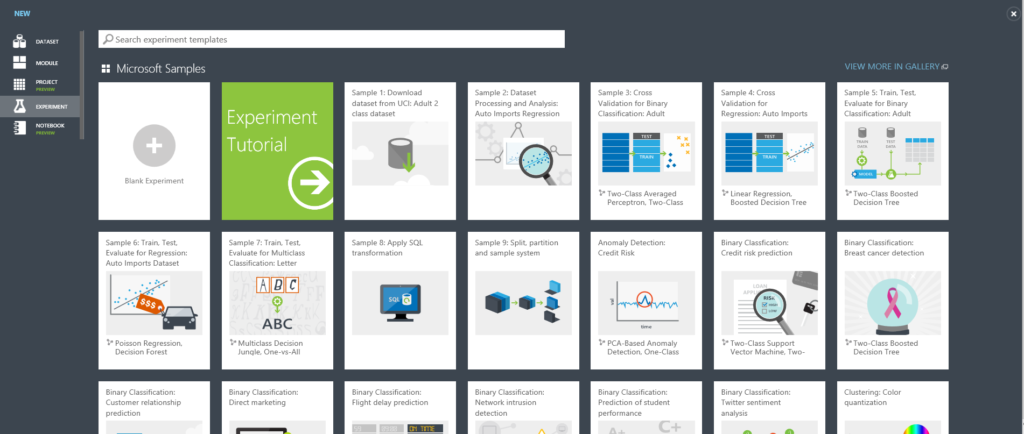
色々とテンプレートがありますが、今回は左上の[Blank Experiment]を選択。
アイテムの配置
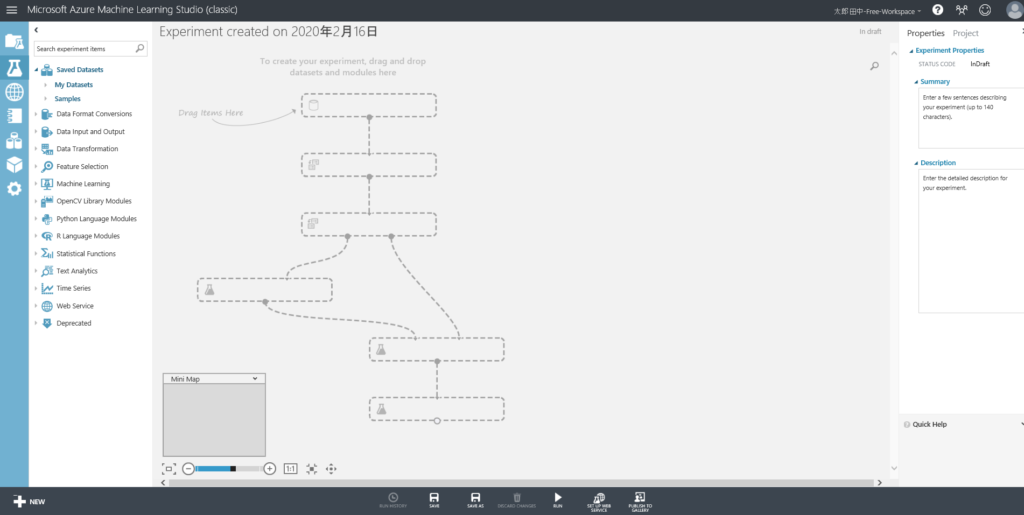
何やらうっすらガイド(Drag Items Hereの文字など)が出ていますが、だいたいこんな感じでパーツを配置して矢印をつないでいく作業です。
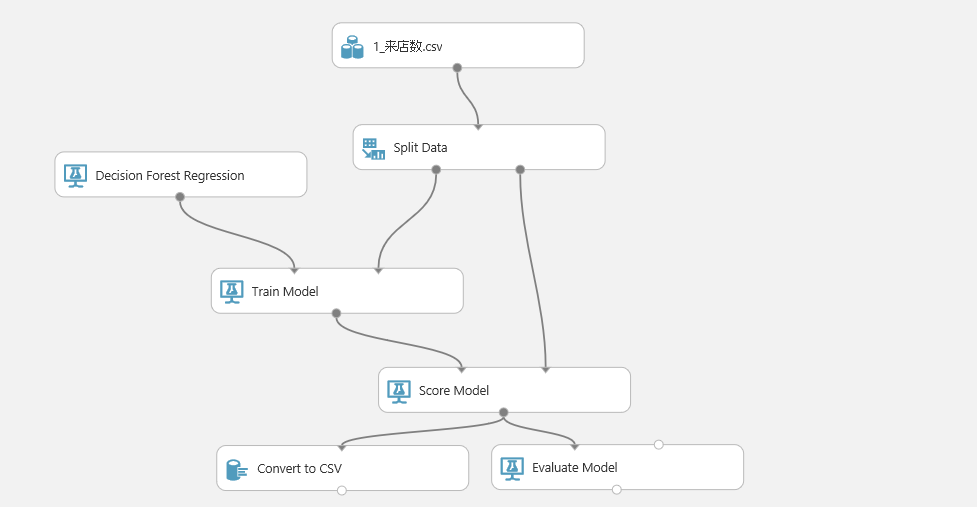
完成しました!
それぞれのアイテムの場所は以下の通り。
- 1_来店数.csv(インポートしたデータ):[Saved Datasets]-[My Datasets]
- Split Data:[Data Transformation]-[Sample and Split]
- Decision Forest Regression:[Machine Learning]-[Initialize Model]-[Regression]
- Trial Model:[Machine Learning]-[Initialize Model]-[Train]
- Score Model:[Machine Learning]-[Initialize Model]-[Score]
- Convert to CSV:[Data Format Conversions]
- Evaluate Model:[Machine Learning]-[Evaluate]
各アイテムのパラメータ設定
各アイテムのパラメータを見ていきます。
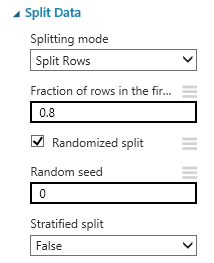
データの分割です。公式ドキュメントはこちら。
今回は、データを8:2に分割したい(ランダム分割)だけなので、上記のような設定とします。
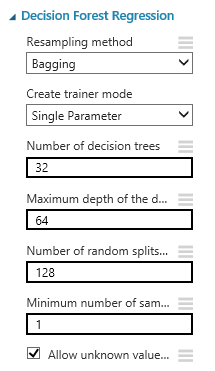
続いてランダムフォレストモジュールですね。今回の肝となる部分です。
公式ドキュメントはこちら。
ツリーの深さや葉の数をパラメータとして指定していきます。
なんだか難しそうに見えますが、以下アイテムで最適なパラメータの数値を探ることもできます。
- Tune Model Hyperparameters:[Machine Learning]-[Initialize Model]-[Train]
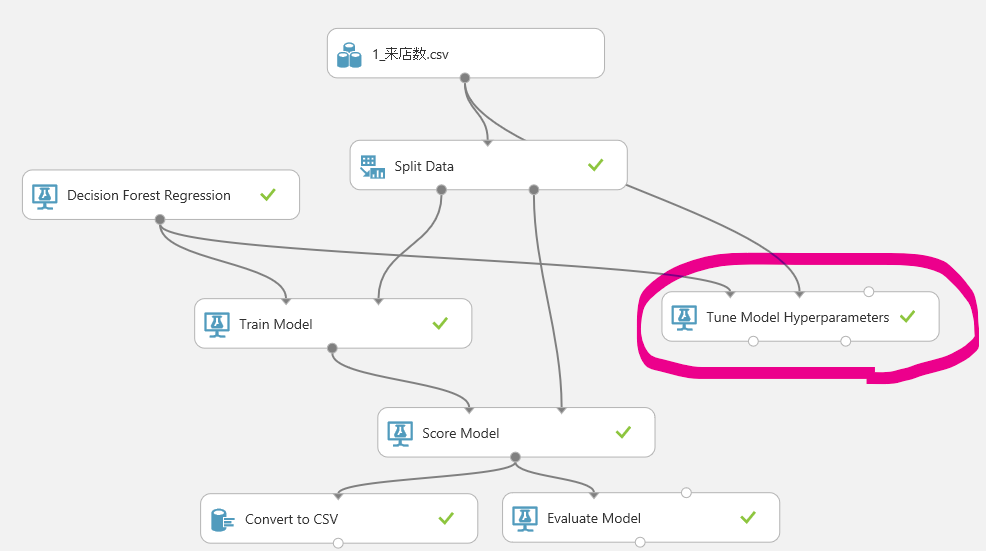

公式ドキュメントはこちら。
今回はsweepの対象を全体(Entire Grid)としていますが、ランダム(Random sweep)のほうが処理時間は短いです。多少時間がかかっても、考え得る組み合わせすべてを試したい場合は、Entire Gridにすると良いです。
ここでひとまず、画面下部の[RUN]をクリック。最適なパラメータを探っている間、しばし待ちます。
完了したら、当該アイテムの①を右クリックして、[Visualize]をクリック。
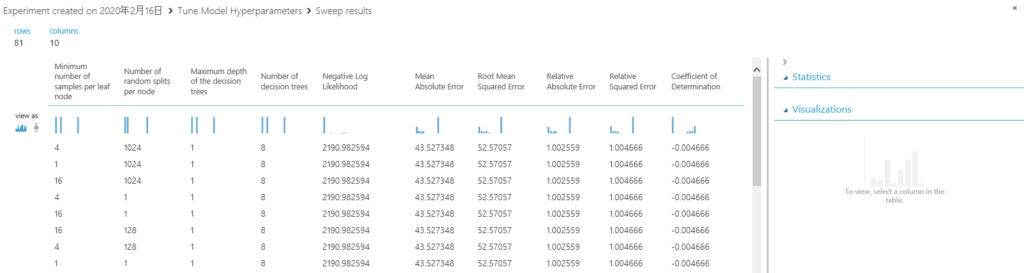
試した組み合わせの結果がずらりと並びます。誤差辺りもこの時点でざっくり判明します。
下にスクロールしていき…、

32,64,128,1でパラメータ設定をすると一番良い結果になりそうですね!
今回も上記の結果をもとに「Decision Forest Regression」のパラメータを指定してみました。

「Train Model」のターゲットは当然、来店数とします。
ランダムフォレストで予測させてみる
さて、改めまして画面下部の[RUN]をクリックすると、学習と予測が始まります。
尚、「Tune Model Hyperparameters」は最適なパラメータが判明したら削除しても良いと思います。
今回ぐらいのデータ量であれば、1分もかからず、すべての工程が完了すると思います。
リソースはクラウド上にあるので、「マシンスペックがボトルネックになって学習が全然終わらない…」みたいなことがないのが良いですね。
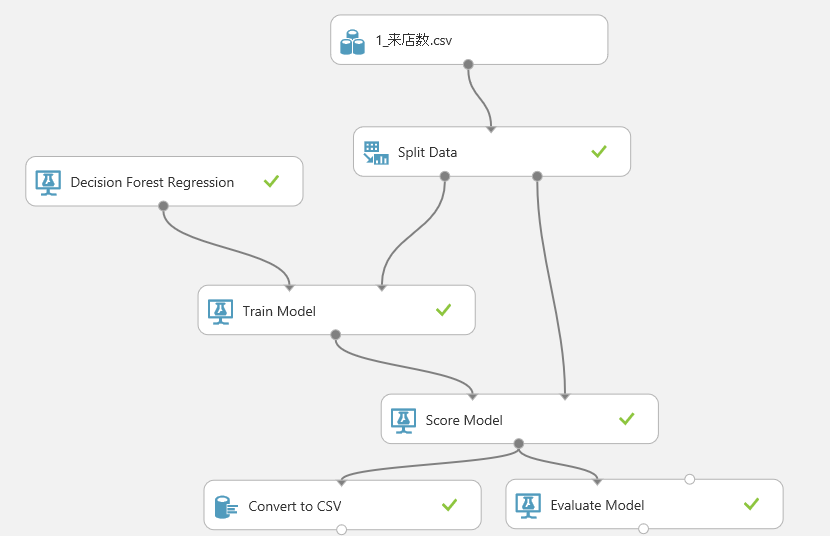
尚、完了した工程にはレ点(チェックマーク)が付きます。
エラーが起きた際に、どこまでが正常終了してどこで問題があったかが追いかけやすくなっています。
予測結果を評価する
結果を見てみましょう。
例によって「Evaluate Model」アイテムの①を右クリックから、[Visualize]します。

SONYの『Prediction One』ではRMSE(平均平方二乗誤差)が31.54でしたので、今回は28.29ということで、この問題(来店数予測)においては更に優秀な結果となりました!
1件ずつの結果を参照する場合は、「Convert to CSV」の①を右クリックし、[Download]。
ダウンロードしたCSVをExcel等で開けば確認できます。
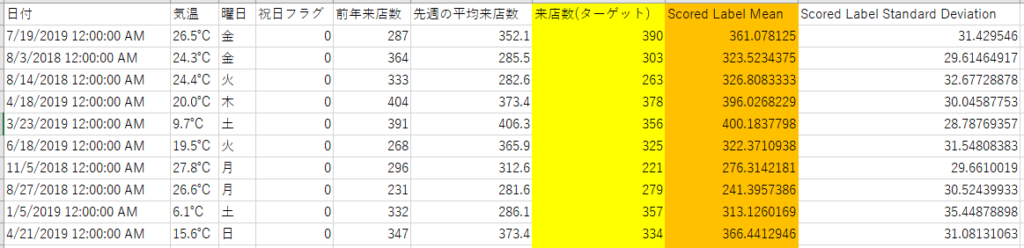
オレンジ網掛け部が予測した来店数、黄色網掛け部が実際の来店数です。
予測データ81件分のそれぞれの数値をグラフ化すると以下のような感じに。紛らわしいですが、横軸は単なるシーケンス番号であり時系列等の意味はないです。
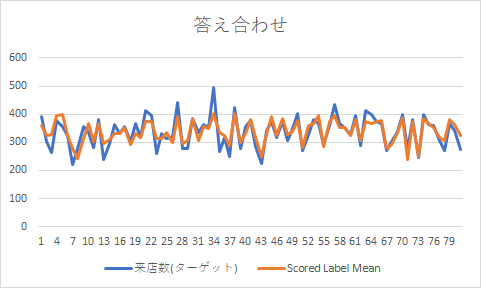
500人来た日はさすがにフィッティングしきれていませんが、グラフで見てもなかなか良い線いっているかと。
また、以下アイテムでどの項目が予測結果に寄与しているかを測ることもできます。
・Permutation Feature Importance:[Future Selection]

配置できたら、画面下部の[RUN]をクリック。
結果は、例によってアイテムの①を右クリック⇒[Visualize]。
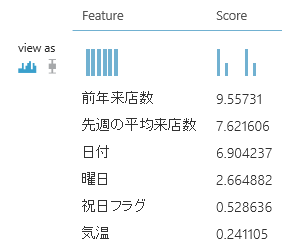
前年の実績が最も誤差平均に影響を与えていることが分かりました。
逆に、スコアが低いものは結果にあまり影響を与えていないということになります。
この結果から、説明変数を増やしたり減らしたりするのも良いですね。
まとめ
今回は、『Microsoft Azure Machine Learning Studio(クラシック)』でランダムフォレストによる予測をさせてみました。
ノンコーディングでここまでの精度が出せれば、かなり有用かと思います。
また、『Microsoft Azure Machine Learning Studio(クラシック)』には、今回触れたアイテム以外にも、まだまだ多種多様なアイテムが用意されています。
予測のアルゴリズムだけで今回試したものを含む8つが用意されていますし、分類問題も解けるようになっていますので、まずはお手持ちのデータをインポートして、ぜひ色々と試してみてください。
それでは、また次回!

平成生まれのアラサー文系ぽんこつシステムエンジニア。
エンジニアらしく技術系の記事を書いたり、全く関係ない記事を書いたり、まったりやっていきたいです。
AI(人工知能)、デジタルマーケティング、DX、Office365活用、ガジェットなどに興味があります。

コメント