

これまでの流れ
準備編は以下記事をご参照ください。

ざっくりの環境構築までを行いました。
今回は、実際に何かしらのデータを用意して、予測をさせてみたいと思います。
『Prophet』で予測してみる
予測をしたいデータの準備
Prophetのインプットデータには制約があり、“ds”(日付)と“y”(値)から
構成されていなければいけません。変数名もこのままでないとダメです。
今回は、気象庁のHPより、東京の平均気温を10年分ぐらい抜き出して、
向こう1年の平均気温の予測をかけてみようと思います。
| ds | y |
| 2009-9-11 | 23.9 |
| 2009-9-12 | 21.4 |
↑こんな感じのデータでOKです。
予測
さて、公式ドキュメント翻訳版のクイックスタート編みたいなことをやります。
ざっくりコード部分をまとめて今回用にカスタマイズしたりして、以下のような感じに。
import pandas as pd
from fbprophet import Prophet
import os
# データが格納されている作業ディレクトリまで移動
path = os.getcwd()
os.chdir("D:\yosoku\\")
path = os.getcwd()
print(path)
# csvの読み取り
df = pd.read_csv("tokyo_tenki.csv")
df.head()
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=365)
future.tail()
forecast = m.predict(future)
forecast['ds'].tail()
fig1 = m.plot(forecast)
m.plot_components(forecast)
# グラフ描画
import matplotlib.pyplot as plt
m.plot(forecast)
plt.xlim(future.ds.iloc[-365], future.ds.iloc[-1])
plt.xlabel('Date')
plt.ylabel('Average')
plt.show()plotできないぞ!というエラーが出たら、以下コマンドでplotlyを最新化します。
・pip install –upgrade plotly
私の環境では、データはDドライブの”yosoku”というフォルダ配下に”tokyo_tenki.csv”という
名前で突っ込んでいます。
向こう1年の予測なので、随所でパラメータは365に。
これを先述のJupyter Notebookに貼り、“Run”を押します!
結果は…
まずは10年分のプロットと向こう1年の予測結果を年スケールで。
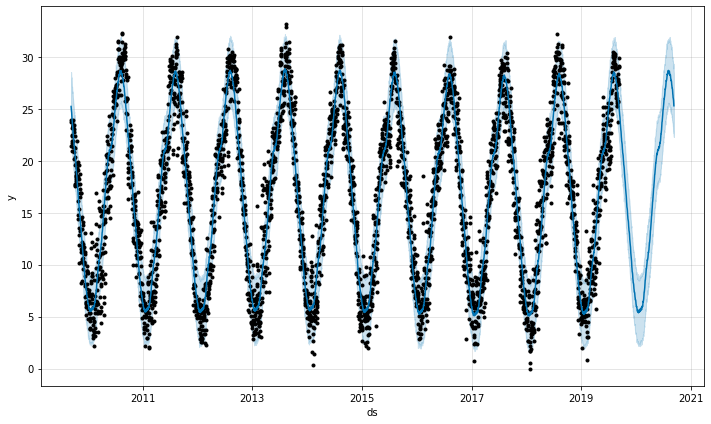
点が多すぎてタピオカみたいになってますが、1粒1粒が日ごとのデータです。
2014年は大雪があったので、突出した点が出たりしてますね。
2019年9月中旬辺りからが予測部分ですが、いい感じで予測できてますね。
水色の領域は80%信頼区間(デフォルト設定時)を示しているそうです。
80%の確率で母平均が水色の領域に収まりますよということですが、詳しくはWeb上の他統計系の記事をご参照ください。
続いてトレンド。
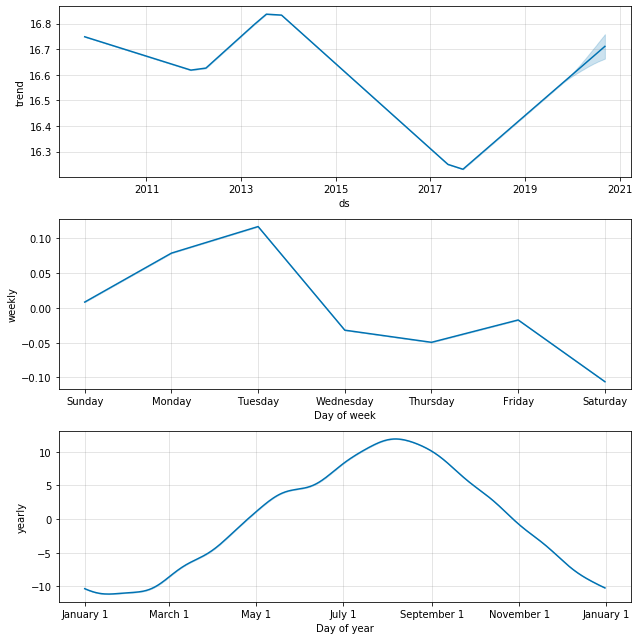
なんとなく上り調子に乗っていきそうですかね。
曜日の差は有意差ではなさそうですが、月ベースだと季節感が出ていますね。
最後に予測部分(向こう1年分)を細かく見たもの。
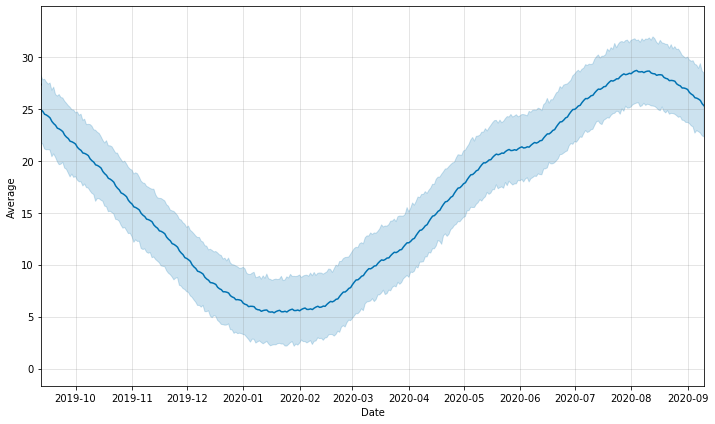
こちらでも季節を捉えていい感じで予測できていると思います。
まとめ
手軽さ十分
準備にもそれほど時間がかからず、すぐに結果が見える点は、とても手軽で良いところ
だと思います。
結果の視覚化もしやすいので、データが手元にあってひとまず分析してみたいときや、
上司の一声で「ちょっと分析してみてよ」などと言われて何かしらのデータを渡されたときにも、
とても役に立ちそうですね。
他サービスについて
先日、同じような時系列予測のサービスで、Amazon Web Services(AWS)より、
『Amazon Forecast』がリリースされました。
従量課金制みたいなので、こちらも時間があればお試しで少し触ってみたいです。
※2020/01/17 追記
2020年1月15日にSONY製の予測分析ソフトウェア『Prediction One』に
時系列予測機能が追加されましたので、試しました。

今日はここまで!

平成生まれのアラサー文系ぽんこつシステムエンジニア。
エンジニアらしく技術系の記事を書いたり、全く関係ない記事を書いたり、まったりやっていきたいです。
AI(人工知能)、デジタルマーケティング、DX、Office365活用、ガジェットなどに興味があります。


コメント